It often happens that scorecard accuracy leaves much to be desired. Moreover, the discrepancy between the expected and actual performance of the scorecard is often noticed at the final stage of it’s implementation, when most of the resources have already been invested.
How can we ensure that everything possible has been done to develop a scorecard of the highest quality, and how can we pinpoint and prevent potential errors?
To answer that question, let us consider the process of developing a scorecard. This process contains the following stages:
- Sampling
- Statistical evaluation of borrowers' characteristics
- Formation of training and validation datasets
- Use of the regressional procedure for scorecard calculation
- Evaluation of the scorecard's quality
We cannot significantly impact the results of the regression algorithm performance by adjusting its parameters. Correspondingly, we cannot influence the performance of the scorecard at the stage of evaluating its quality.
Hence, the first three stages dealing with the processing and preparation of the credit portfolio data are the most important.
Let’s look at a few ways we can locate and prevent errors that will have a negative impact on the quality of the scorecard.
1. Sampling
This stage starts by downloading borrower-related data from a data warehouse.
At this stage it is important to preserve the main requirements for the working sample: its representativeness and randomness.
Representativeness means the maximum accuracy of the borrower's characteristics contained in the sample in relation to the actual borrower's characteristics in the credit portfolio. This requirement is absolutely natural, since the scorecard reflects the specifics of the dataset used for its development.
Randomness means that loan application data should be included into the working sample independently.
In practice, the working sample is formed by randomly selecting credit cases corresponding to the select timeframe, from the data warehouse.
In this situation, the timeframe selected for the working sample is a decisive factor. To better understand this fact, let's consider the mechanism of forecasting based on the time factor:
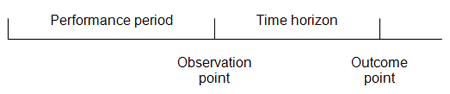
Performance Period — the period of time during which we collect information on the credit quality of borrowers. It ends with the observation point that corresponds to the moment of the forecast.
Time horizon – the borrower's credit quality is determined at the end point (outcome point) of the time horizon.
For example, if the observation period is 12 months and the time horizon is 6 months, based on the analysis of the borrower's behavior during the 12 months we can predict his/her state in 6 months.
Here we need to pay attention the following factors: the observation period must be uninterrupted and historical data must be close to the actual characteristics of the credit portfolio.
2. Statistical evaluation of borrowers' characteristics
Statistical evaluation of the borrower's characteristics involves the analysis of distribution and statistical characteristics of the borrower.
At this point, special attention must be paid to unnaturally distributed indicators, including:
- Characteristics with one prevailing category of borrowers
- Characteristics with few (down to one) categories of borrowers
- Characteristics that demonstrate an obvious gap between the borrower share and actual characteristics present in the credit portfolio
When unnaturally distributed characteristics in the credit portfolio are found we need to adjust the procedure of forming the working sample and define the rules for assigning values to the indicator.
The next step involves defining the predicting capability of borrower characteristics.
For that purpose, we use the IV indicator.

The analysis of the prediction capability of characteristics is performed in accordance to the following scale:

To improve the situation, we can adopt the following measures:
- Change the set of categories for the corresponding borrower characteristics
- Calculate new borrower characteristics based on the existing ones
In addition, using the so-called product of characteristics is also an effective method. For example, using the Salary and Experience characteristics, we can calculate the field that contains "Salary>5000 & Experience>4", "Salary
We should pay special attention not only to the low predicting capability of borrower characteristics, but also a very high reference.
The following features more often than not indicate potential errors in the formation of the working sample:
- high predicting capability of the borrower's demographic characteristics (for example, presence of dependents, number of family members, etc.)
- high predicting capability of the characteristics of the granted loan (for example, its duration)
- high predicting capability of the borrower's regional characteristics
Selection of training and validation datasets
The correct choice of training and validation datasets directly impacts the quality of the scorecard. Special attention must be paid to their selection.
The main condition for the training dataset selection is a sufficient number of examples of both "good" and "bad" loan cases.
While the number of records can be lower, it is important to preserve the ratio of "good" and "bad" records. For example, using the standard regression procedure, we can create a scorecard based on 1,500 records.
The procedure of training and validation datasets selection is simple enough.
1. The working sample is randomly subdivided into two non-intersecting datasets with the volumes of 80% and 20% (for bigger datasets it can be 70%-30% or even 50%-50%). The bigger dataset is to be used to train the scorecard, the smaller one is used for the purpose of validation.
To ensure a higher quality of results, older data are used to form the training dataset, while the validation dataset is created based on more recent data.
2. If the volume of resulting datasets is not large, they are directly used in the regression procedure.
If the volume of the training and validation datasets is large, we randomly form subsets of smaller volumes (from 3,500 to 4,000) to be directly used in the regression procedure.
If the working sample contains a certain small category of borrowers, it is important to control that corresponding records are included into the training and validation datasets, since using automatic selection procedures may result in including the entire number of representatives of small categories into the training dataset, which prevents us from adequately evaluating the performance of the scorecard using the validation dataset.